Het belang van Data Quality voor een Data Centric Way of Working
Gebaseerd op een recent Statista-onderzoek uit 2023 gehouden onder loyale klanten over de hele wereld, zijn de belangrijkste aankoopfactoren: een overvloedig productaanbod (81%), productbeschikbaarheid (80%), het privacybeleid van de data (79%) en een goede klantenservice (77%).
Het is duidelijk dat een nauwkeurig begrip van de customer experience van groot belang is. Om de ervaringen van klanten effectief te monitoren en geïnformeerde beslissingen te kunnen nemen, heb je betrouwbare data nodig voor informatie en inzichten. Het adopteren van een data centric manier van werken is de manier om dit te bereiken.
Uiteindelijk biedt data jou en je teams informatie en klantinzichten om de klantervaring te verbeteren. Om het gedrag van je klanten te kunnen waarnemen en deze kennis te gebruiken om het klanttraject te verfijnen, moet je 100% op data vertrouwen. Een data centric aanpak hanteren waarbij iedereen vertrouwt op klantgegevens is essentieel.
Dit artikel gaat dieper in op verschillende veelvoorkomende risico's die samenhangen met het handhaven van de datakwaliteit. Ook de noodzakelijke voorwaarden voor het behoud ervan, zoals het effectief beheren van data privacy en compliance, en de criteria voor het opzetten van een data centric organisatie worden behandeld.
De meest voorkomende data kwaliteitsrisico's
- Per ongeluk persoonlijk identificeerbare informatie (PII) gebruiken, zoals e-mailadressen van jouw betalende klanten opnemen in de URL-parameters. Het overtreden van de AVG-wetgeving met boetes en reputatieschade is een gevolg. Niet erg gebruikelijk, maar brengt een extreem hoog risico met zich mee. Vorig jaar hebben we dit al een keer gezien.
- Belangrijke beslissingen kunnen niet volledig worden ondersteund met bruikbare informatie vanwege het verlies van analytische metingen na een ontwikkelings update. Een gat in de data (een week of zelfs langer) is bij meerdere organisaties een gangbare praktijk. En zoals je je kunt voorstellen, maakt dit het moeilijker om te vertrouwen op lange termijn analyses, omdat je geen conclusies kunt trekken op basis van analyses van jaar tot jaar in dezelfde periode. We zien deze uitdagingen elk kwartaal verschijnen.
- Overdaad aan gegevens en trackingmethoden: Met de overvloed aan gegevens die tegenwoordig beschikbaar is, raak je gemakkelijk overweldigd door de enorme hoeveelheid informatie. Het is belangrijk om prioriteit te geven aan het verzamelen van gegevens die aansluiten bij de doelstellingen en KPI's van jouw organisatie. Bovendien kan een gestroomlijnde aanpak van trackingmethoden bijdragen aan het garanderen van consistentie en nauwkeurigheid.
- Attributiemodellen en discrepanties: Verschillende advertentie- en social mediaplatforms hebben vaak verschillende attributiemodellen, wat leidt tot discrepanties in de gerapporteerde cijfers. Het opzetten van een gestandaardiseerd attributiemodel of het begrijpen van de verschillen tussen platforms kan de verwarring helpen verminderen. Het regelmatig controleren en vergelijken van gegevens uit verschillende bronnen kan ook helpen bij het identificeren van inconsistenties.
- Gebrek aan consistentie in de rapportage en het definiëren van KPI's: Consistentie in de rapportage is cruciaal voor het opbouwen van vertrouwen in datagestuurde beslissingen. Het hebben van gestandaardiseerde rapportage sjablonen, -richtlijnen en -protocollen kan ervoor zorgen dat gegevens op consistente wijze door alle afdelingen heen worden geïnterpreteerd.
Idealiter zouden Key Performance Indicators (KPI's) en tracking methoden consistent voor de hele organisatie moeten worden gedefinieerd. Dit bevordert een uniform begrip van de doelstellingen en zorgt ervoor dat iedereen naar dezelfde doelstellingen toewerkt. Het is echter belangrijk om enige flexibiliteit toe te staan om zich aan te passen aan specifieke afdelingsbehoeften, terwijl de afstemming op de algehele organisatiestrategie behouden blijft.
Beheersing van gegevensprivacy en compliance
Een juiste configuratie leidt tot privacy en compliance. Onjuiste privacy-instellingen kunnen ervoor zorgen dat er onbedoeld gevoelige gegevens worden verzameld en opgeslagen. Het beheersen van gegevensprivacy en compliance betekent ervoor zorgen dat privacy-instellingen correct worden geconfigureerd en onderhouden om te voldoen aan de toepasselijke wetgeving, zoals de AVG.
Boetes en reputatieschade wil je uiteraard voorkomen. Het gebruik van een AVG-monitor, inclusief een dashboard met real-time waarschuwingen, kan hierbij helpen door automatisch toezicht te houden op de aanwezigheid van persoonlijk identificeerbare informatie (PII) in de gegevens.
Wie heeft toegang tot welke persoonlijk identificeerbare informatie (PII)?
Een cruciaal aspect van compliance is het nauwkeurig gebruiken van gebruikersrechten en het op de juiste manier beheren van de toegang tot GA4-gegevens. Verkeerd omgaan met gebruikersrechten en toegangscontroles kan leiden tot ongeautoriseerde toegang tot GA4-gegevens.
Het is absoluut noodzakelijk om de toegang strikt te beperken tot geautoriseerde gebruikers om te voorkomen dat gevoelige gegevens in verkeerde handen vallen. Dit helpt datalekken en mogelijke juridische gevolgen te voorkomen.
Het belang van het continu volgen en opslaan van waardevolle gegevens
Een goede analyse-implementatie is uiteraard vereist om gegevens te verzamelen en op te slaan om informatie en uiteindelijk inzichten te verkrijgen. Aan de ene kant zien we dat veel data als ‘van onschatbare waarde’ worden bestempeld vanwege de verkeerde manier waarop de data is verzameld. Wetende dat je maar één kans hebt om het correct te verzamelen; de manier waarop je gegevens verzamelt moet goed zijn voordat het verzamelen begint.
Onderhouden is een andere noodzaak. Aan de andere kant zien we vaak dat historische informatie niet meer beschikbaar is vanwege een onjuiste instelling van de bewaartermijn. Nu zijn trends niet meer te ontdekken en is waardevolle analyse niet meer mogelijk.
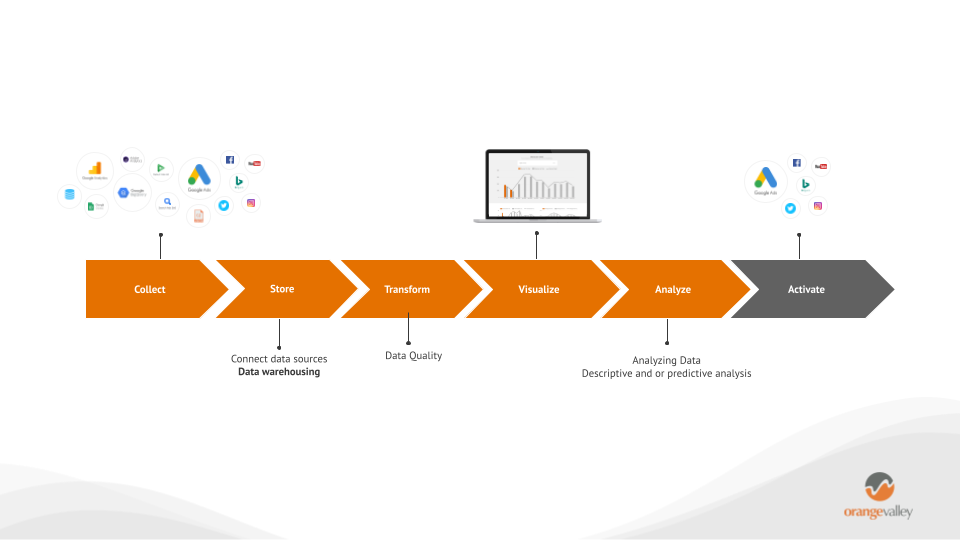
Het opzetten (incl. onderhouden) en dataopslag zijn de eerste twee fasen van het 6-fasen datamodel. Deze eerste twee stappen zijn ‘verzamelen’ en ‘opslag’ van gegevens essentieel. De latere stadia; Het ‘transformeren’, ‘visualiseren’, ‘analyseren’ en laat staan ‘activeren’ van data is niet mogelijk zonder de eerste sterke data fundamentals; ‘verzameling’ (zowel opzet als onderhoud) en ‘opslag’ (op basis van correcte bewaartermijnen).
Hoe datakwaliteit behouden?
Omdat leveranciers van analyse platforms voortdurend de bestaande functies op hun platform veranderen of nieuwe lanceren, kampen organisaties vaak met een verouderde analyse-opstelling. Dit maakt waardevolle data onbruikbaar, wat leidt tot een verspilling van data-investeringen.
Om dit probleem tegen te gaan, houdt een geautomatiseerde data kwaliteitsmonitor nauwlettend toezicht op jouw analyse configuratie, waarbij real-time meldingen aan het team worden verstrekt wanneer aanpassingen nodig zijn. Dit mechanisme garandeert het handhaven van strenge data kwaliteitsnormen tegen minimale kosten.
Hoe kun je gegevensverlies minimaliseren?
Met behulp van een data kwaliteitsmonitor kun je automatisch trends in de gegevens van vandaag vergelijken met die van de vorige dag. Door je dagelijkse gegevens te vergelijken, ontvang je cruciale waarschuwingen, zodat je gevallen kunt identificeren waarin een conversie (vorige voltooiing van het doel) is gewijzigd als gevolg van wijzigingen op jouw website.
Het vergelijken van dagelijkse verkeersgegevens met bijvoorbeeld flag-tagging-problemen kan vervolgens direct worden opgelost. Het zorgt ook voor een naadloze stroom van kwalitatieve gegevens naar jouw gegevens opslaglocatie. Vervolgens kan het proces van het transformeren, visualiseren en analyseren van data beginnen.
Hoe doe je een betrouwbare data-analyse: het bekende ‘360 klantbeeld’
Om een betrouwbare data-analyse uit te voeren, moet je er allereerst voor zorgen dat gebeurtenissen correct zijn ingesteld en dat filters nauwkeurig zijn geconfigureerd om betrouwbare rapporten te garanderen. Een verkeerde configuratie kan resulteren in onnauwkeurige gegevens en analyses wanneer bijvoorbeeld bepaalde gebeurtenissen of verkeer worden uitgesloten. Dit kan leiden tot verkeerde conclusies, slechte besluitvorming en gemiste kansen voor verbetering.
In de toekomst omvatten aanvullende aandachtsgebieden het begrijpen van het onderscheid tussen universele analyses en GA4, het navigeren door de complexiteit van de verschillende gerapporteerde conversiecijfers en het construeren van attributiemodellen.
Het verschil tussen Universal Analytics- en GA4-uitvoer
We hebben allemaal de verschillen gezien tussen de output in Universal- en GA4-analyses. Deze verschillen resulteren in een afname van het vertrouwen in data onder onze collega’s; de mensen die we willen overtuigen van onze analytics-inzichten.
Er is ook een verschil tussen de gegevens die worden weergegeven in de GA4-interface en de onbewerkte gegevens. Hoewel Google zou kunnen zeggen dat ze je alle gegevens laten zien, laat GA4 je niet 100% zien. De reden hierachter is de focus op snelheid. Google wil concurreren met andere analyse platforms op basis van laadtijd in de interface. Eén techniek die ze gebruikten om dit te bereiken, is het schatten van sessies. Dit is gebaseerd op een kleinere subset van de gegevens. Dit verklaart ook de verschillen tussen UA- en GA4-uitvoer.
Waarom verschillen de gerapporteerde conversiecijfers op sociale platforms van die op jouw analyse platform?
Je hebt wellicht de verschillen opgemerkt in de manier waarop conversies worden toegeschreven aan betaalde advertenties of sociale kanalen. Waarom rapporteert TikTok bijvoorbeeld een hoger aantal conversies dan jouw analyse platform? Ook binnen ons bureau is META een veelgehoorde naam als er gesproken wordt over verschillen in conversie rapporten.
Deze verschillen komen voort uit het onderliggende bedrijfsmodel van de advertentie- en social platforms. Ze profiteren van een hoger aantal conversies. Hoe de conversies aan het platform worden toegewezen en waarom het aantal conversies verschilt, is te wijten aan attributie.
Er worden verschillende methoden gebruikt die krediet toekennen aan verschillende marketingkanalen of contactpunten langs het conversiepad. GA4 gebruikt nu drie verschillende attributiemodellen:
- Standaard kanaalgroep voor nieuwe gebruikers: Eerste klik
- Standaard kanaalgroep voor sessies = Laatste klik
- Standaard kanaalgroep voor conversies = Data Driven
Bouw jouw eigen attributiemodel
Je kunt jouw organisatie de controle geven over de uitdagingen die voortvloeien uit de verschillen tussen attributiemodellen door je eigen attributiemodel te creëren en te beheren. Als je alle beschikbare GA4-data volledig wilt benutten, kan het gebruik van BigQuery een haalbare optie zijn.
Door de integratie van de BigQuery plugin kan de ruwe data gebruikt worden. Met behulp van SQL kan jouw team de rapportageopties die beschikbaar zijn in GA4 reproduceren en zelfs aanpassen. Dit maakt het mogelijk om op regels gebaseerde marketingattributiemodellen te definiëren en te gebruiken, met behulp van logica waarvan jij de eigenaar bent en die jij kunt wijzigen. Dit plaatst jou aan het stuur van attributie!
Wat zijn de voorwaarden die nodig zijn om te transformeren naar een data centric organisatie?
Terwijl datagestuurde digitale marketing zich richt op het gebruik van data als hulpmiddel, gaat data centric digitale marketing een stap verder door data zelf als een waardevol bezit te beschouwen. Het betekent dat je data moet zien als een essentieel bedrijfsmiddel dat centraal staat bij het nemen van beslissingen en het ontwikkelen van marketingstrategieën.
Het verzamelen, opslaan en beheren van gegevens is de sleutel tot het verkrijgen van waardevolle inzichten in klantgedrag en trends. Een data centric aanpak is essentieel voor organisaties die willen groeien en concurreren in een digitale omgeving. Door data als een waardevol bezit te zien, kunnen bedrijven zich onderscheiden van hun concurrenten en waardevolle inzichten verwerven die leiden tot effectieve marketingstrategieën en een betere klantervaring.
De vier fundamentele aspecten voor een data centric organisatie
- Onderhoud: Datakwaliteit is goed ingericht en constant onderhouden;
- Kennis: uniform begrip onder alle belanghebbenden van het bedrijf met betrekking tot bijgehouden elementen en de betekenis van verschillende statistieken;
- Toepassing: Iedere medewerker weet data te gebruiken waar relevant en mogelijk;
- Vertrouwen: het bevorderen van een gevoel van vertrouwen op en afhankelijkheid van gegevens in de hele organisatie.
Een voorbeeld dat illustreert hoe onze klant alle belanghebbenden in de hele organisatie helpt bij het begrijpen van zowel de bijgehouden elementen als de verschillende statistieken, is door het gebruik van een 'KPI-catalogus'. Deze catalogus omvat alle triggers en definities van maatregelen, gepresenteerd in een begrijpelijke taal voor alle belanghebbenden binnen hun organisatie.
Conclusie
Onderzoek onderstreept het grote belang van datakwaliteit in een data centric benadering van het bedrijfsleven. Het begrijpen van de voorkeuren van klanten, het nemen van beslissingen en het verbeteren van klantervaringen zijn afhankelijk van nauwkeurige en betrouwbare gegevens.
Data privacy, consistentie en juiste configuratie spelen een cruciale rol bij het handhaven van de gegevenskwaliteit.
Organisaties moeten sterke data fundamentals, geautomatiseerde kwaliteitsmonitoring en betrouwbare analyse-implementatie neerzetten om de uitdagingen het hoofd te bieden en de voordelen van een data centric aanpak te ontsluiten.
Vertrouwen, kennis, toepassing en onderhoud zijn de hoekstenen van een dergelijke transformatie, waardoor effectieve besluitvorming en superieure klantbetrokkenheid mogelijk zijn.
Betrouwbare data en het vertrouwen in data van werknemers zijn van fundamenteel belang voor het bouwen van bloeiende data centric organisaties in de toekomst.